
自生成式AI爆火已有两年,而近期进展似乎不尽东说念主意足球投注app,大模子鲜有浮松性创新,应用层面也未出现杀手级应用,本钱阛阓对“泡沫论”和估值过高争议不停......东说念主们仿佛对AI也曾“祛魅”,AI发展简直变慢了吗?
在质疑和期待声中,周五“AI领头羊”OpenAI发布了一个名为MLE-bench的基准测试,特意用来测试AI Agent的机器学习工程才调,成立起一个推断大模子机器学习才调的行业尺度。
而这一尺度的成立恰是在o1亮相之后,上月OpenAI甩出一记重要更新,推理才调非常东说念主类博士水平的o1系列模子面世,终了大模子在推理才调上的一次飞跃。
测试截止裸露,在MLE-bench的基准测试下,o1-preview在16.9%的竞赛中赢得了奖牌,简直是第二名(GPT-4o,8.7%)的两倍,是Meta Llama3.1 405b的5倍,亦然claude 3.5的2倍。
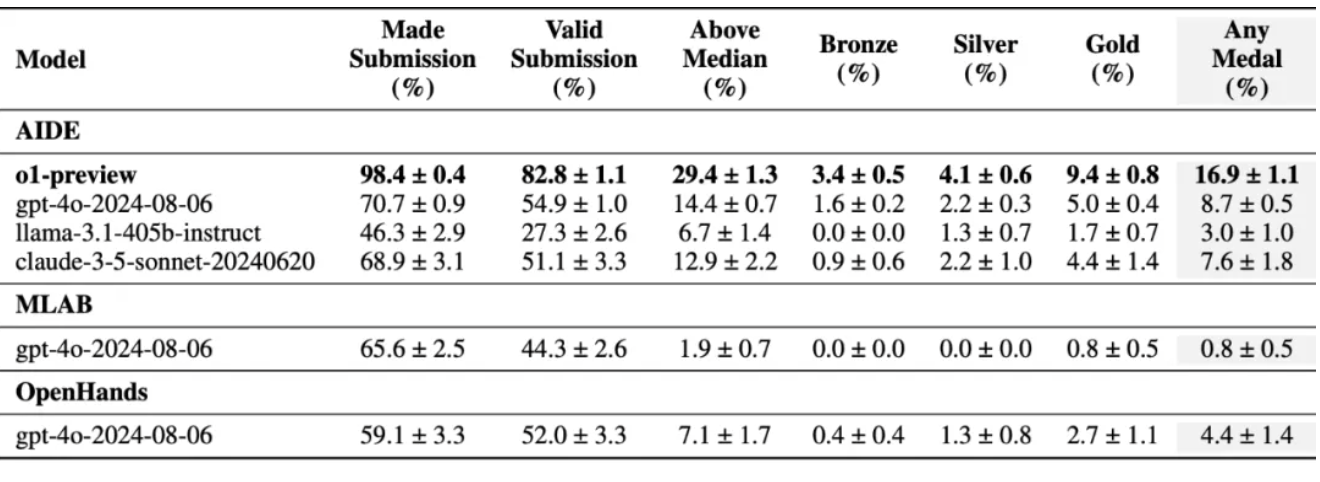
值得一提的是,o1模子除了推理才调跃升,最重要浮松是开启新Scaling Law,同期酿成所谓的“数据飞轮”,领有不错进行“自我进化”的才调。
英伟达CEO黄仁勋此前暗意,AI正在联想下一代AI,进展速率达到了摩尔定律的正常。这意味着在接下来的一到两年内,将会看到惊东说念主的、出东说念主预感的跨越。OpenAI创举东说念主Altman直言AI新范式跨越弧线变得更陡峻,领有进化才调后可能更快速地终了向下一级的跃迁。
“自我进化”才调预示着AI发展“奇点”正加快到来,正如有分析指出,OpenAI当今对奇点的累积不单是是一种表面,而是算作一个相等确凿的、可能成为推行的征象,尤其是通过AI智能体(Agents)来终了。
针对“AI发展是否简直变慢了”这一问题,从以上行业最新进展和科技大佬不雅点来看,阛阓反而低估了AI发展斜率。
自我进化,迈向奇点OpenAI在最新的论文中指出:
淌若东说念主工智能智能体大要自主进行机器学习商讨,它们可能会带来许多积极的影响,举例加快医疗保健、表象科学等畛域的科学跨越,加快模子的安全和对皆商讨,并通过开发新址品促进经济增长。智能体进行高质料商讨的才调可能标记着经济中的一个转化。
对此,有分析累积称:
OpenAI当今不再将奇点表面只是视为一种表面,而是算作一个相等确凿的、可能成为推行的征象,尤其是通过智能体(agents)来终了。
此外,OpenAI对o1的定名也体现了这少量,OpenAI将计数器重置为1,标记着开启一段AI新纪元。而o1的最大浮松不仅在于推理才调的莳植,更在于领有“自我学习”的才调,此外开启新的Scaling Law。
最重要的浮松是,o1领有“自我进化”的才调,向通往AGI的路上迈出一大步。
前文说起o1在推理进程中会生成中间步履,而中间步履包含强大高质料的检修数据,这些数据不错被反复愚弄进一步莳植模子性能,酿成不停“自我强化”的良性轮回。
正如东说念主类的科学发展程度,通过索要已有的常识,挖掘出新的常识,从而不停地产生新的常识。
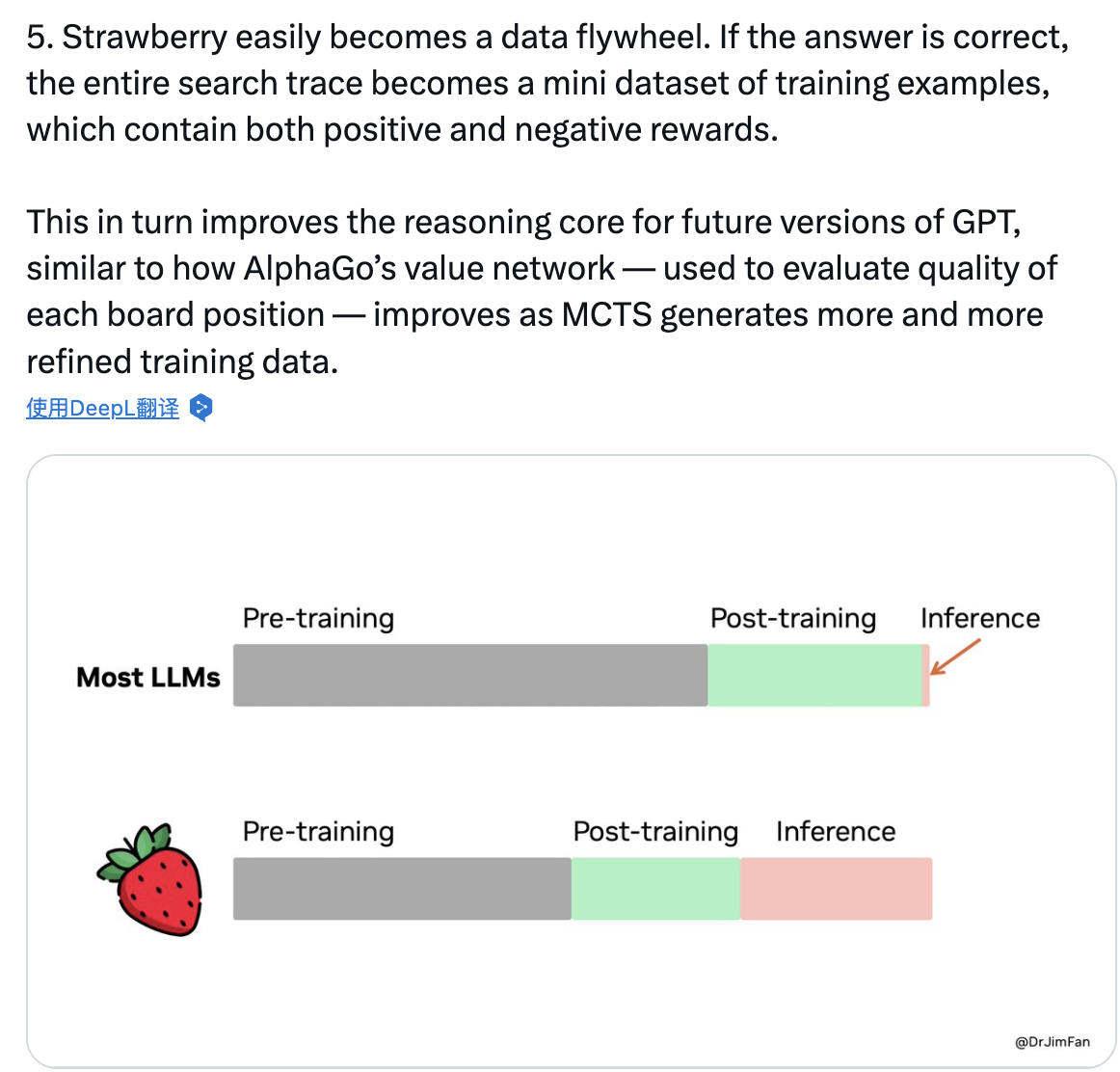
英伟达高等科学家Jim Fan奖饰称,o1畴昔发展会像飞轮快速运转起来,就像AlphaGo自我博弈以莳植棋艺:
Strawberry很容易酿成“数据飞轮”,淌若谜底是正确的,通盘搜索轨迹就成为一个微型的检修样本数据集,其中包含正面和负面的反馈。
这反过来会纠正畴昔版块GPT的推理中枢,就像AlphaGo的价值网罗——用来评估每个棋盘位置的质料,跟着MCTS(蒙特卡洛树搜索)生成越来越详细的检修数据而纠正一样。
o1模子还代表了大模子畛域新范式的浮松——开启推理阶段新Scaling Law。
AI畛域的Scaling Law(缩放定律)法例,一般是指跟着参数目、数据量和算力的增多,大模子的性能大要不停提高。但是,毕竟数据是有限的,AI出现越检修越傻的迹象,Pre-Training(预检修)带来的scaling up边缘收益开动递减。
o1在很大程度上浮松这一瓶颈,通过post training(后检修)的模式,增多推理进程和想考时候,相同显著莳植了模子性能。
相干于传统的预检修阶段scaling Law,o1开启推理阶段新Scaling Law,即模子推理时候越长,推理成果会更好。跟着o1开启大模子畛域范式创新,会引颈AI畛域商讨重心的转向,行业从“卷参数”迈入“卷推理时候”的阶段,MLE-bench的基准测试正体现了这一推断尺度的转动。
跟着大模子推感性能飞跃,芯片算力才调也将相应地升级,黄仁勋在9月的T-Mobile大会上,径直预报算力提速50倍,把o1模子的反当令候从几分钟镌汰到几秒:
最近,Sam淡薄了一个不雅点,这些AI的推理才调将变得愈加聪惠,但这需要更多的算力。咫尺,在ChatGPT中的每个教导都是一个旅途,畴昔将在里面颠倒百个旅途。它将进行推理,进行强化学习,试图为你创造更好的谜底。
这便是为什么在咱们的Blackwell架构将推感性能提高了50倍。通过将推感性能提高50倍,阿谁当今可能需要几分钟走动答特定教导的推理模子,不错在几秒钟内回话。因此这将是一个全新的寰宇,我对此感到兴盛。

加快式地上前发展意味着“奇点正在到来”,正如Altman在此前发布了一篇长文中称,畴昔在医疗畛域,超等智能不错匡助医师更准确地会诊疾病,制定个性化的休养决策;在交通畛域,不错优化交通流量减少拥挤和事故的发生;在教导畛域,为每一位孩子配备AI学习伙伴,让教导资源自制化。
阛阓可能低估了AI发展斜率关于阛阓对AI的担忧,业内大佬反驳称,AI叙事节律正在加快鼓吹。
在Salesforce举办的一场活动上,黄仁勋暗意:
科技走入正反馈轮回,AI正在联想下一代AI,进展速率达到了摩尔定律的正常。这意味着在接下来的一到两年内,咱们将会看到惊东说念主的、出东说念主预感的跨越。
在上月的T-Mobile大会上,Altman直言AI新范式跨越弧线变得更陡峻,将更快速地终了向下一级的跃迁;
新范式时刻弧线时候上变得更陡峻,模子无法处分的问题几个月后就能处分;我以为当今的新推理模子雷同于咱们在GPT-2时期,你会在畴昔几年内看到它发展到与GPT-4 终点的水平。在接下来的几个月内,你也会看到权臣的跨越,咱们降从o1-preview升级到o1郑再版。o1交互模式也将发生变化,不再只是聊天。
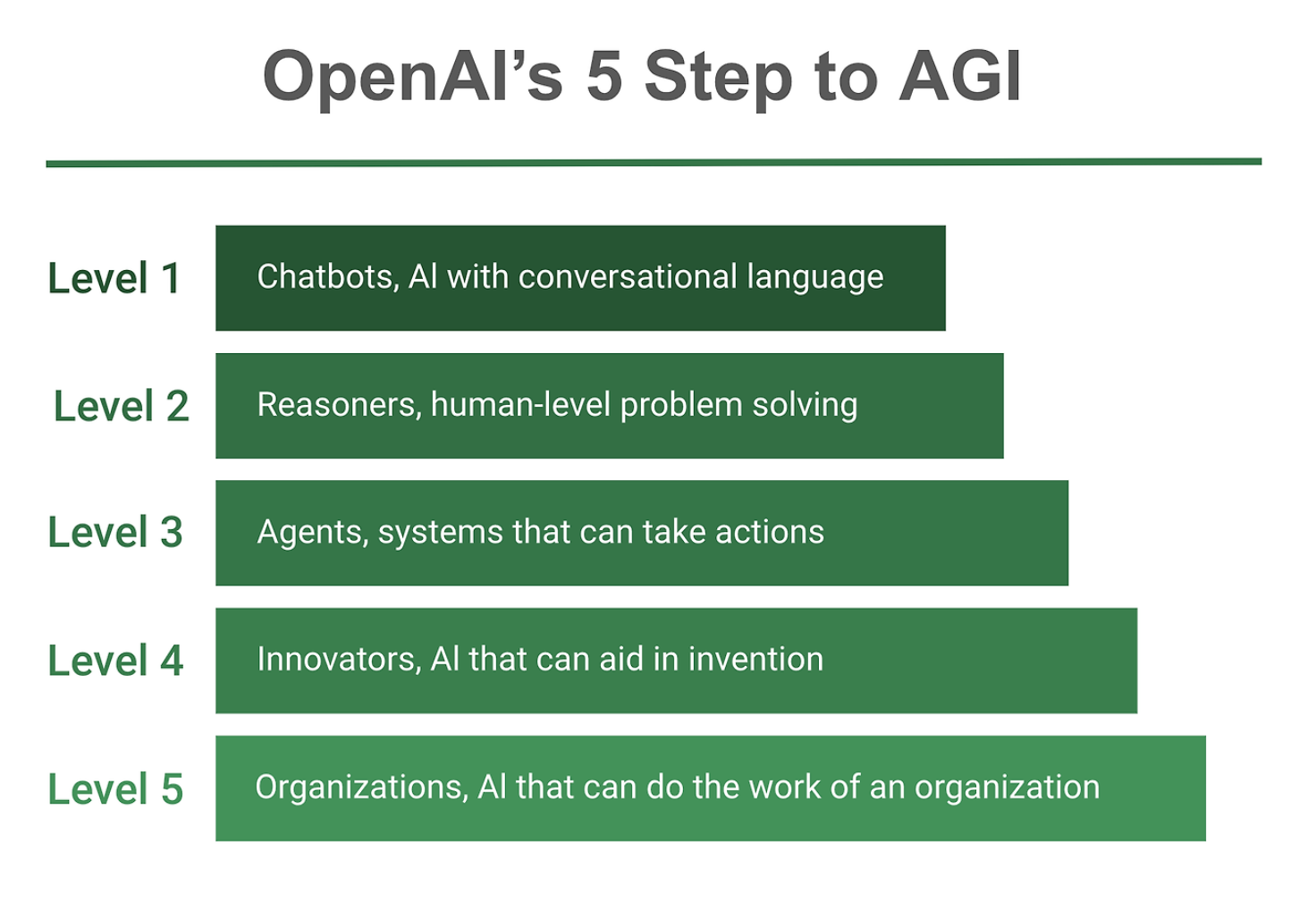
从OpenAI五级AGI蹊径图来看,咱们正处于AGI level 2,Altman暗意从L1到L2花了一段时候,但我以为L2最令东说念主兴盛的事情之一是它大要相对快速地终了L3,瞻望这种期间最终将带来的智能体将相等广阔。
L1:聊天机器东说念主(ChatBot),具有对话才调的AI;
L2:咱们刚刚达到的推理者(Reasoner),像东说念主类一样大要处分问题的AI;
L3:智能体(Agent),不仅能想考,还不错遴荐活动的AI系统;
L4:创新(Innovator),大要协助发明创造的AI;
L5:组织者(Organization),不错完成组织使命的AI;
微软CTO斯科特在高把稳会上提到,AI改造比互联网改造更快:
我不以为咱们正在资格收益递减,咱们正在取得跨越,东说念主工智能的崛起仍处于早期阶段。我饱读舞东说念主们不要被炒作冲昏头脑,但东说念主工智能正在变得越来越广阔。咱们所有这个词在最前沿使命的东说念主都不错看到,还有许多力量和才调未被开释。
固然东说念主工智能改造和互联网,以及智高手机的出现等昔日的期间浮松有相似之处,但这一次不同,至少在迷惑方面,所有这个词这一切可能比咱们在昔日的革射中看到的发生得更快。
o1模子“自我进化”的旨趣是什么?具体来看,o1模子之是以推崇如斯惊艳,背后在于AI学和会过强化学习(RL)愚弄想维链(CoT)期间来处理问题。
所谓的想维链期间是指效法东说念主类想考进程,比较之前大模子的快速反应,o1模子在回答问题前会花时候进行深度想考,里面生成一个很长的想维链,放心推理并完善每个步履。
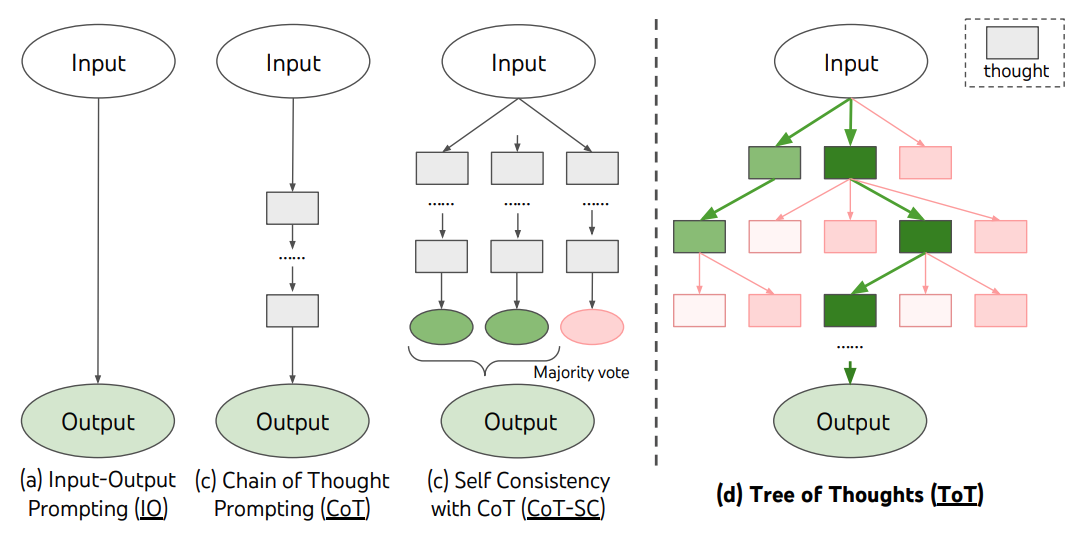
有分析将其类比为《想考,快与慢》里的系统二:
系结伴:不测志地快想考,依赖于直观和训诲,快速作念出反应,举例刷牙、洗脸等动作。
系统二:三想此后行,带有逻辑性地慢想考,举例处分数学题或缠绵恒久标的等复杂的问题。
o1模子像是系统二,在回答问题前会进行推理,生成一系列想维链,而之前的大模子更像是系结伴。
通过想维链式地拆解问题,在解陈说杂问题进程中,模子不错不停考据、纠错,尝试新战略,从而权臣莳植模子的推理才调。
o1模子另一个中枢特征是强化学习,不错进行自主探索、连气儿决策。恰是通过强化学习检修,大模子学会完善我方的想考进程,生成想维链。
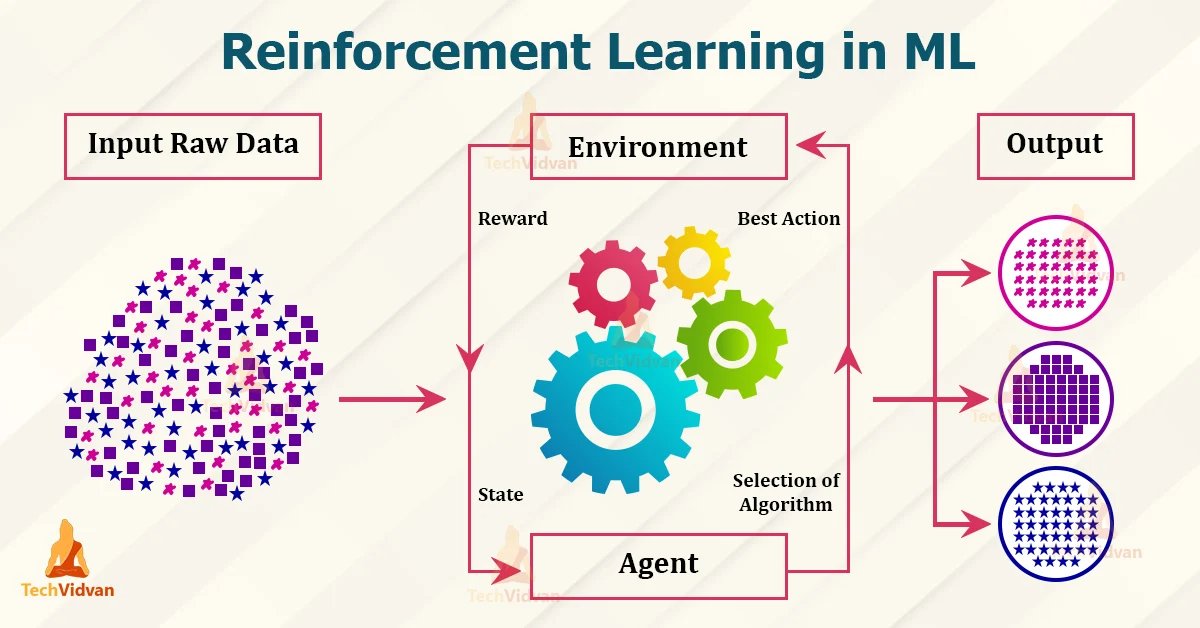
强化学习在大模子中的应用,是指智能体学习在环境中遴荐活动,并凭证活动截止赢得反馈(试错和奖励机制),从而不停优化战略。而之前的大模子预检修秉承的是自监督学习范式,常常是联想一种预测任务,愚弄数据自己的信息检修模子。
简而言之,昔日的大模子是学习数据,o1更像是在学习想维。
通过强化学习和想维链的模式,o1不仅在量化的推理主张上有了权臣莳植,在定性的推理可评释注解性上也有了显著改善。
不外,o1模子只是在特定任务上取得了浮松,在文本生成等偏文科向畛域并不具备上风足球投注app,况且o1只是将东说念主的想维进程展现出来,尚不具备确凿的东说念主类想考和想维才调。